真实世界研究指南2018年版(全文)
时间:2020-06-05 17:23 来源:吴阶平医学基金会 作者:中国胸部肿瘤研究 点击:次
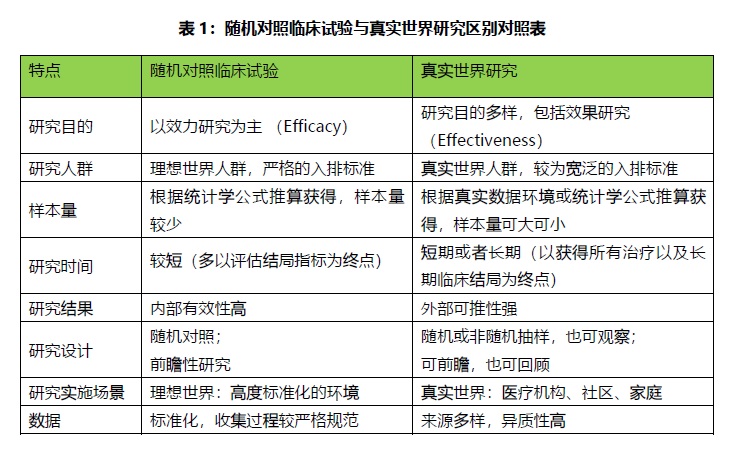
一.背景 近年来,国内外对真实世界研究(RealWorldStudy,RWS)的关注度日益增加。首先,从政策层面看,美国食品药品监督管理局(FoodandDrugAdministration,FDA)于2016年7月27日发布《采用真实世界证据支持医疗器械的法规决策》草案,几经修订到2017年8月31日发布最新版[1],该指南表明了FDA对真实世界证据用于医疗器械法规决策中的态度。国家食品药品监督管理总局(ChinaFoodandDrugAdministration,CFDA)也于2017年10月8日出台了《关于深化审评审批制度改革鼓励药品医疗器械创新的意见[2],提到为满足临床急需药品医疗器械使用需求,加快审评审批,允许可附带条件批准上市,上市后按要求开展补充研究,此类补充研究也可部分归属于RWS范畴。 其次,从医疗大环境看,医疗大数据的构建给RWS提供了前所未有的便利。各级医疗机构、医保部门、医药监管部门积累了大量的医疗数据,各级数据库的电子化,以及各种电子设备的普及,各级数据库平台的建立,极大地增加了利用高质量数据进行真实世界研究的可能性。另外,患者、医生、医疗保险提供方、监管者以及政策制定者都在努力寻求各种来自于特定人群药品使用的准确信息。而RWS则将成为药品临床应用、医保制定、决策制定等各方参考的重要依据。 虽然RWS越来越多受到各方的重视,但因目前大多医疗数据分布零散,没有进行系统性收集和结构化处理,RWS所需样本量相对较大,数据异质性强,混杂和干扰因素多,对研设计和统计方法的要求比传统研究更高。更重要的是,我国目前尚没有系统性的指南对RWS提供建议和指导,故如何帮助中国研究者更好地开展RWS研究,提高RWS质量,是编写本指南的初衷。本指南为国家重点研发计划项目(项目编号:2016YFC1303800)和国家公益性行业专项(项目编号:201402031)。 二.几个重要概念的关系 1.真实世界证据与真实世界数据 真实世界数据不等同于真实世界证据。真实世界数据通过严格的数据收集、系统的处理、正确的统计分析以及多维度的结果解读,才能产生真实世界证据。美国FDA在评估真实世界数据能否成为真实世界证据时需要看其数据的质量,包括真实世界数据与其结果的相关性以及可靠性等[1]。 2.真实世界研究与随机对照临床试验 RWS是对临床常规产生的真实世界数据进行系统性收集并进行分析的研究,与随机对照临床试验(RandomizedControlledTrial,RCT)是互补的关系,并不对立。RWS和RCT一样,都需要科学合理的研究设计,研究方案以及统计计划。另外判断RWS和RCT的标准不是试验设计和研究方法,而是研究实施的场景[3]。RWS数据源自医疗机构、家庭和社区等,而非存在诸多严格限制的理想环境。RWS与RCT相比,各具特点,详见表1:
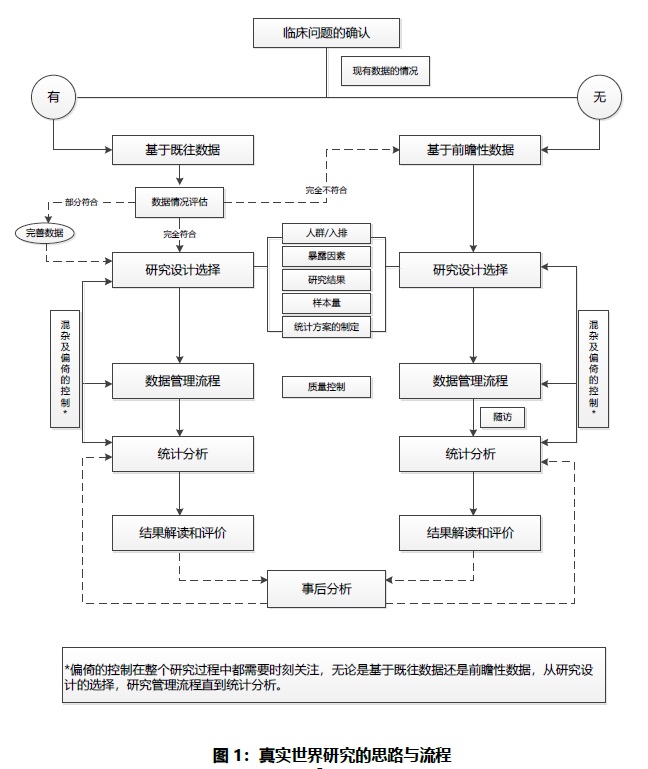
三.真实世界研究的思路与流程 RWS的开展须从临床问题的确定、现有数据情况的评估切入(采用既往回顾性数据或是前瞻性采集数据,进一步到研究设计的选择以及统计分析方法的确定、数据的管理、统计分析、结果解读和评价、以及根据需求判断是否加入事后分析(Adhocanalysis)等步骤(见图1)。由于RWS可能存在一些内在的偏倚(Bias),这些偏倚可能限制了真实世界数据在因果关系上的推理和解读。因此,为了减少潜在的偏倚,需要谨慎而周密的研究设计,并且应该确定研究问题后尽早开始制定研究方案和统计分析计划。
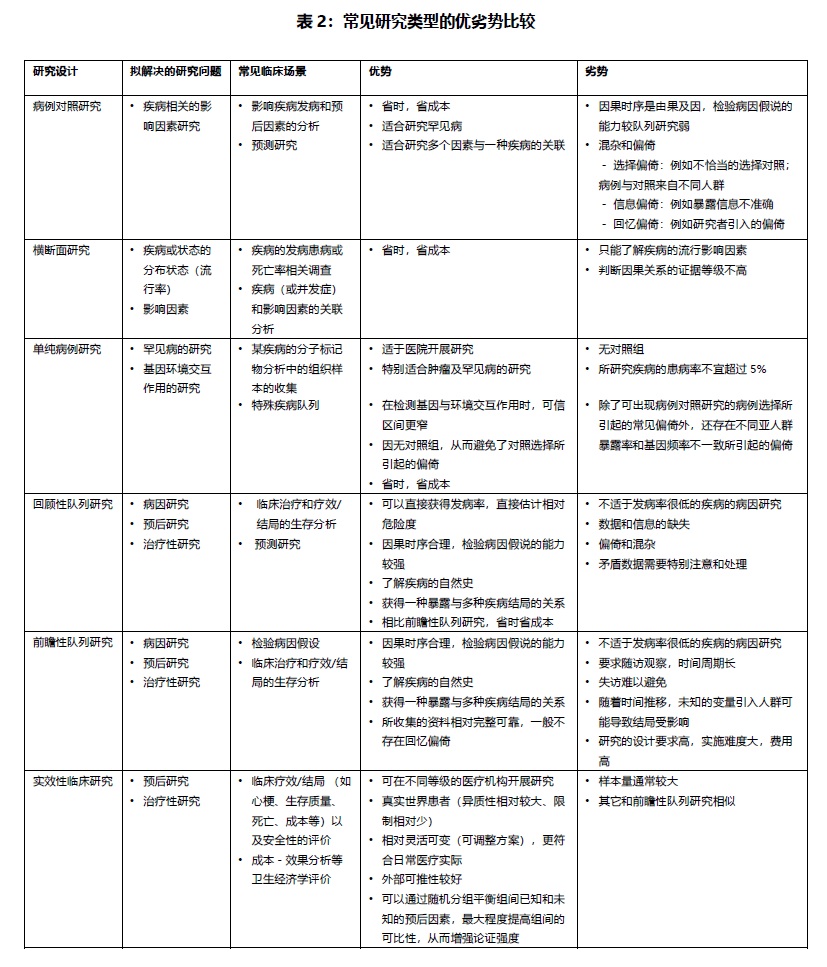
四.临床问题的确定和研究设计常见类型 RWS通常会围绕着病因,诊断,治疗,预后及临床预测[4]等相关的研究问题展开。病因研究主要是研究危险因素与疾病之间的关系,并研究引起人体发病的机制,如研究幽门螺杆菌感染与十二指肠溃疡的关系。诊断研究主要是研究某类新方法对特定疾病诊断的准确度研究,以判断新诊断方法的临床价值。治疗性研究主要是研究某类治疗方案对特定疾病的疗效及副作用研究。主要包括两方面:①治疗方案对特定疾病的疗效研究;②治疗方案的不良反应研究。预后研究是对疾病发展的不同结局的可能性的预测以及与影响其预后的因素研究,主要包含三大类:①对疾病的预后状况进行客观描述;②对影响预后的因素进行研究;③对健康相关生活质量的研究。临床预测研究则是寻找出最佳的对疾病诊断或疾病转归的预测指标或症状等,主要包括诊断预测研究和预后预测研究。除上述研究外,RWS也会涉及药物经济学研究等其它研究类型。 RWS包括观察性研究和试验性研究。其中观察性研究进一步分为描述性研究(病例个案报告、单纯病例、横断面研究)和分析性研究【(巢式)病例对照研究、队列研究】,试验性研究即实效性临床研究(Pragmaticrandomizedclinicaltrial,PRCT)。除此以外,一些新型的研究设计如病例交叉设计和序贯设计等也被用在基于现有数据的研究中。下表是常见研究类型对应的临床应用场景及优劣势比较,供参考。
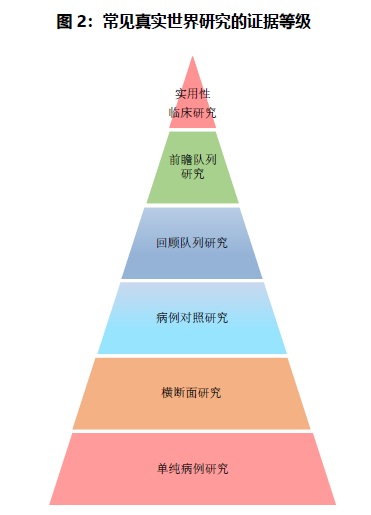
五.基于不同数据源的研究要素 1.基于现有数据 1.1现有数据利用 现有数据主要包含电子病历(electronicmedicalrecord,EMR),电子健康档案(electronichealthrecord,EHR),医保数据(claimsdata),出生死亡登记,公共健康监测数据以及区域化医疗数据等,这些数据数量非常庞大,但由于数据的采集并非为某特定研究目的而设计,数据分散,异质性高,数据的完整性及准确性也存在一些问题。另外医保数据一般由各级政府机构掌握,可及性较弱。 1.2数据可行性评估 数据可行性评估首先基于待研究的临床问题,确定主要研究变量比如待研究的治疗措施,关键基线信息,主要研究结局包括患者主要人口统计学特征、患病史、并发症、合并症和实验室指标等关键数据是否存在;其次对缺失数据的数量和类型的影响进行全面评估,包括主要研究变量及其他相关研究变量,可以通过抽样或全数据集来检查关键变量的数据缺失程度和模式来实现。另外还需进行数据质量评估:包含数据的准确性,可靠性,完整性及可溯源性等评估。 1.3研究设计的考量 研究人群和入排标准 回顾性队列和病例对照研究中,首先需要确定研究对象尤其是对照的选择和入排标准的设定。病例对照研究中,对照应尽量选择内部对照,选择没有发生研究结局的人群,且与病例来自同一人群;对照的选择不受暴露因素的影响,即除了暴露因素外,对照应与病例在其他特征上相似;病例对照比例可以从1:1到1:4不等。单纯病例研究设计则无需对照组。回顾性队列设计中,须根据研究问题清晰定义暴露,比如可以是有/无某治疗方案,暴露的程度如剂量,或者暴露的模式如顺序等等。非暴露组的人群应在除了暴露因素外与暴露组尽可能相似。在确定研究人群的标准后,要在数据库中使用一定的算法和代码来识别研究人群,如ICD编码和药品编码。值得注意的是,任何一种编码由于不同机构医疗水平或者电子病历系统平台不同,对于疾病诊断的准确性和完整性都会有所不同。因此,综合各项编码和实验室诊断等联合的识别方式,是基于数据库开展研究的常用方法。 暴露因素和研究终点 暴露因素和研究终点是研究中首要考量的关键因素。在数据可行性评估及纳入和排除研究对象的阶段之后,进一步确认暴露状态及研究终点的准确性和代表性,是否有不同数据佐证关键数据的准确性。如果研究基于已有病例数据,则需特别注意收集数据的完整性、真实性和可溯源性;如果研究基于患者的自我报告或者研究者的回忆,则须强调数据的准确性和真实性,以防出现回忆偏倚。 样本量 RWS同样需要将样本量的估计作为不可缺少的设计要素之一。对于存在假设检验的分析性研究(如病例对照设计、队列设计等),如果样本量不足,会导致没有足够的把握度(power)去检验提出的问题和假说。基于不同研究类型需要依据不同的统计分析方法,确定重要参数,定义I类错误和把握度,在保证研究具有一定可靠性条件下,估计并确定最小样本量,确保研究同时具备科学性和经济性。另一方面,RWS往往采用较宽泛的纳排标准,有时需要随访较长时间来来研究长期临床结局,充分反映实际的临床实践,因此应在确定最小样本量的基础上,尽可能地扩大样本量以保证其能够覆盖更广泛的患者群体并考虑到较长随访时间导致的失访的可能性。在具有异质性的患者群体中可进行亚组分析,从而拓展研究的意义。具体样本量的估算需要在临床医生、统计师和流行病学家等的合作下共同完成。 统计方法的考量 应在研究问题确定后,尽早制定研究方案和统计分析计划,将解决主要研究目的统计方法纳入。RWS的统计方法和疗效比较研究(Comparativeeffectivenessresearch,CER)[5]的分析方法有类似之处。因RWS接近临床实际,研究对象的纳入限制较少、人群的异质性较大、自主选择治疗措施等造成潜在偏倚和混杂,因此统计方法更多是关注如何减小和控制偏倚和混杂。常见的有匹配、分层分析和多变量分析。在较多风险因素或者研究因素的情况下,使用多变量分析将多个因素同时纳入模型,会由于共线性等问题,使得模型无法正常运行。倾向性评分匹配(propensityscorematching)或者分层(stratification)则是解决该类问题的常用统计方法。成本效益模型、贝叶斯模型等也常应用于RWS的研究设计中。 另外,利用已有数据库开展的预测研究也是常见的RWS类型之一,是对疾病各种结局发生概率及其影响因素的研究。传统的统计方法包括Logistic回归和Cox回归以及列线图(nomogram),可以用来预测疾病转归或者并发症的发生概率;另外,近年来发展出的基于真实世界大数据的机器学习(machinelearning)的方法也是用于预测研究的常用工具。 处理缺失数据 在RWS中,数据的缺失是一个不可避免的问题。预防策略和统计调整可以减少缺失数据对研究结果的影响,提高结果的可靠性。关注不同研究类型可能出现的数据缺失也可帮助减少缺失数据对研究结果影响。 使用电子EHR、EMR或者医疗保险等数据源会出现不同的问题。由于研究者往往无法采集额外的数据,因此研究前数据可行性评估是非常重要的环节。例如,对于临近死亡的患者,症状可能记录不完整,而这种缺失信息可能使这些患者的相关数据看上去比实际状况更健康而造成研究偏倚。有时数据的缺失并非随机的,如果忽略缺失数据的内在规律,那么会丢掉重要的信息。对于缺失数据,在能够溯源的情况下,则尽可能补全相应缺失数据;对于无法溯源的情况,则展开探索性分析,明确缺失值在各个研究因素中的分布情况,判断其分布是否随机,如有偏倚,则需考虑后期分层分析。 1.4其他常见问题 不同数据库整合的问题 对于不同数据库的整合,一般建议首先对各自数据库中数据进行质量评估和分层分级,确定好需要整合的内容。在整合过程中,矛盾的数据是重中之重,需要重点关注。建立统一的数据标准,将不同数据库的数据结构进行标准化处理。在整合过程中对于无法整合的数据进行处理,同时需要注意因整合造成的系统误差,以及关注整合后的主要研究因素,暴露因素及主要混杂因素的影响。 分子标记物相关研究的注意事项 开展分子标记物相关的RWS,由于采集生物样本的难度以及其测量的特殊性,研究设计需要注意以下的问题。 基于已有数据库的回顾性研究需要考虑患者的基线特征和代表性的问题,由于缺失的生物样本而导致的数据缺失,多重检验导致的“假阳性”结果,数据分析和结果解释中的偏倚,以及研究结果是否具有可重复性等。 前瞻性的研究则需考虑,可能有生物样本但是没有详细的患者基本信息的情况;样本量小,且患者人群缺乏代表性;实验检测方法是否经过验证;有分子标记物测量结果,没有或仅有有限临床结局数据(如总生存率,无进展生存期等)的情况;临床数据或者研究终点数据的质量等。 用数据库开展研究,知情同意和伦理审批的相关事宜 真实世界研究的数据收集,患者的信息有可能会成为研究资料,因此患者本身在某种程度上可能也已成为“受试者”,所以真实世界研究同样需要符合伦理的要求。因此某些情况下,真实世界研究也需获得伦理审查委员会的备案或批准。 知情同意是保证研究符合伦理要求的一个重要环节,它是一个持续的完整过程,保护受试者权益。因真实世界研究多不是预设方案,尤其是回顾性研究,收集的大量信息多属于历年数据,且涉及到对大规模病例或是生物样本数据进行研究,所以获得每一位受试者同意其数据用于临床的研究有很大的挑战。如果经伦理审查,认为课题研究不大于最小风险,且研究者使用受试者数据不会对患者造成不利的影响和受试者重要隐私信息的泄露,一般可考虑免除知情同意[6,7]。知情及伦理的相关具体要求需根据各伦理委员会的实际要求而定。 2.基于前瞻性数据 2.1前瞻性数据 前瞻性数据主要包括如临床试验的补充数据,PRCT,注册登记研究(Registry),健康调查,公共健康监测等,该类数据在收集之前已确定具体的研究目的,需要收集的数据也很明确,故数据比较规范比较标准,完整性准确性比较好。 2.2研究设计的考量 基于前瞻性数据的RWS一般采用队列研究的设计,队列研究的展开首先起始于要研究的问题,基于健康结果的病因或者风险因素的假说,通过对研究对象的追踪,观察不同群组健康结局的发生情况,进而建立暴露因素和健康结局的联系。 临床研究中,往往有计划地招募患者参加,进而随访患者疾病的复发、好转、痊愈、死亡等,研究不同的治疗或者某些疾病特点是否和不同疾病结局的相关关系。前瞻性队列研究的样本量和随访时间同样重要,研究的样本量越大,随访的时间越长,观察到的健康结局数量越多。开展前瞻性队列研究的主要考虑因素有以下几点: 研究人群的选取 疾病注册或患者注册登记就是系统性地收集某些特点的患者,比如某些诊断、治疗或疾病症状等,这样的登记研究可能使用患者的病历记录和相关信息,而不是所有的可以获得的庞大的数据。不同的疾病注册登记的样本量或者收集信息的深度和广度可能是不一样的,可能是一个单中心或多中心的研究。考虑到不同的研究目的和执行的可能,这样的研究也可以设定一些入排标准。一般来说,严格的入排标准,是为了加强研究本身的内部有效性(internalvalidity),宽泛的入排标准,会提高研究结果的广泛代表性或外推性(externalgeneralizability)。可能很难做到研究结果的内部有效性和外推性两全其美,在设计阶段,如何入选患者需要在临床医生和流行病学家等合作下共同完成评估资源和操作的可能性,平衡研究的内部有效性和外部可推性。 基线调查的研究内容的尽量丰富完整 前瞻性队列研究的基线研究,本身也是一个横断面的研究。在计划和展开研究早期阶段,可以考虑是否要利用横断面信息,一方面回答具体的科学问题,提示未来继续研究的基础;另一方面,也是对数据的可行性和部分数据质量的检验。在这一分析过程中,应该特别关注对主要暴露因素,甚至暴露水平的测量和评估。例如主要暴露因素效度的研究(validationstudy),为未来的主要研究目的的分析奠定质量基础。另外,在考虑收集主要研究暴露因素和相关基线数据之外,应该考虑未来研究拓展的潜在可能性,尽可能收集丰富完整的数据。这样的基线数据会定义患者在研究基线时间点更多的暴露因素和暴露水平,使验证研究假说或研究其他问题成为可能。最后,基线信息的完整采集,对于在后续分析阶段控制偏倚和混杂有重要的作用。 样本量和研究深度的平衡 有些情况下,前瞻性队列研究限于研究条件,研究某些科学问题受限于样本量小,没有足够的把握度来验证假说,在这种情况下,鼓励多个群组研究的共同研究(cohortconsortium),来扩大样本量,促进科研合作。同时,研究的大样本也相应地减少了抽样误差。在小样本量研究的情况下,尽可能在数据采集的深度上努力,在创新性方面做出探索。具体样本量计算可根据研究实际情况在临床医生、流行病学家和统计师的合作下共同完成。 提高患者依从性,长期随访患者 前瞻性队列研究可能会随访数十年,未来研究的健康结局不仅可能包括电子病历、死亡记录、保险登记等电子化平台提供的信息,也应该包括未来可能随访等获得的信息。有些研究时间可能会超过研究者最初计划的跟踪时间,所以提高患者依从性,避免失访至关重要: 充分知情:患者脱落或失访的两个常见原因分别是不良反应或频繁检查,让患者充分了解研究流程,提前告知可能不良反应并进行相应预防措施可有效提高患者依从性。 人文关怀:研究过程中的医患互动,可以发放健康信息,更新研究结果等,争取患者的配合;可帮助患者及时解决研究中碰到的相关问题,增强医患间的相互了解,提高患者依从性。 定期提醒:定期系统或人工提醒可提高患者用药及访视的依从性。 多种沟通方式:保留患者及家属多个长期的联系方式,包括住址,手机,微信,电子邮箱,线上等,并及时更新,可有效避免患者换号后导致的失访。对于失访的患者,也应在不同时间段电话或者通过其它联系方式争取,减少失访。 失访及缺失数据考量 研究者需要在研究开始时针对缺失数据制定计划,尽可能防止数据缺失,同时为处理重要变量的缺失数据制定计划。 失访是前瞻性队列研究的一个重要问题。在研究随访期间,某些研究对象由于各种原因不能或不愿意,或者死亡等原因不能继续参与研究。在需要长期随访的研究中,失访发生的可能性更高,需要更加重视。一般来说,失访低于5%的时候,引起的偏倚比较小,但是失访超过20%的时候,就必须加以重视和分析。如果失访的原因与暴露因素和研究结局有关联,即便是<20%的失访也可能会引起偏倚[8]。如果失访的原因是完全随机的,和暴露因素以及研究结果没有联系,失访低于60%一般是可以接受的。如果失访在某些明确因素的条件下是随机的,而且低于60%,在分析阶段,通过对这些确定因素的分层分析,可以控制失访带来的偏倚。此外,即便失访不一定会带来偏倚,仍会影响研究的准确性,或者说导致研究可信区间变宽。因此,存在失访的情况下,应该进一步分析暴露组和非暴露组失访比例是否有显著性不同,失访是否会和一些关键指标存在关联,进而判断失访条件下得到的研究结果是否低估或者高估了实际情况。 2.3其他衍生研究类型 队列研究中的巢式病例对照研究 巢式病例对照研究是在现存队列研究基础上的病例对照研究。在随访研究人群后,选择新发患者作为病例,然后通过年龄和性别等因素配比,选择对照组,进而比较病例和对照的暴露因素是否不同,来研究疾病和暴露的关系。一般来说在暴露因素的测量难度大、费用比较高或者病例比较罕见的情况下,适用选择巢式病例对照研究。 实效性临床研究 尽管实效性临床研究(PRCT)在RWS中划分在试验性研究,然而其研究设计和前瞻性队列研究有相似之处。其主要用于常规临床实践中疗效对比研究,另外,成本效果分析(cost-effectivenssanalysis,CEA)也是PRCT的关键组成部分。随机化分组是PRCT的关键,用来提高组间可比性,减少选择偏倚。通常选择两种待比较的临床干预措施或方案,采用相对宽泛的入选标准,允许不同研究对象间存在临床异质性,以保证试验结论能最大程度地外推。研究中干预方案的低标准化是PRCT重要特征之一,即研究在实际临床情况或常规临床实践下进行,并尽可能减少对常规治疗的干预。PRCT对照组很少选用安慰剂,通常选用常规或目前公认最佳的临床治疗方法[9]。1954年美国病毒学家J.Salk主持实施的临床研究“索尔克脊髓灰质炎疫苗试验”(Salkfieldtrialofthepoliovaccine),以及2015年由NationalPatient-CenteredClinicalResearchNetwork主导的“阿司匹林心血管获益研究”(AspirinStudy,ADAPTABLE),都属于PRCT[10]。 六.数据管理流程及数据质量控制 1.数据管理流程 RWS研究流程管理的核心整体来说还是加强数据质量,提高研究效率,控制研究成本。研究者可充分发挥软件,移动端和人工智能结构化等新技术功能。加强电子数据采集系统(EDC)定制,增强系统逻辑核查功能,让系统自动进行数据核查,时时保障数据质量;从研究设计层面应该减少不必要的随访和检测,尤其是来院随访。充分利用在线随访功能,即充分让患者参与,让患者报告结局,自动进行患者随访提醒、问卷量表推送,患者端数据采集及医患沟通,提高随访效率和质量;数据点分级管理,强制性保证关键数据的收集的准确真实性。从研究监查与技术层面进行技术创新:使用移动APP进行数据源收集,线上中心化录入配合文本识别(OCR)和智能结构化功能以节约录入成本。同时远程监查以减少差旅成本。 2.数据质量控制 数据质量控制是确保研究数据真实、准确、可靠的关键。研究各个阶段都需要对可能影响数据质量的各个因素和环节进行控制,涉及从数据收集、处理、到统计分析报告的全过程。参照数据质量评价ALCOA+原则[11-13],数据的可溯源性、完整性、一致性、及准确性等指标在在RWS尤为重要,需要重点关注。数据质控则需要建立完善的RWS数据质量管理体系、完善的标准操作流程(SOP)以及人员定期的培训。主要包括: 保证数据源质量,确保数据源信息的完整性和准确性,减少数据源本身的缺失和偏差。临床病历作为关键数据源,其不仅要符合病历书写规范、医院三级质控要求等,还应提高病历质控标准以满足科研需要。 在采集数据前,制定详细的研究设计方案和分析计划。评估确立采集字段,确认关键字段已被收集,制定相应的CRF和数据库架构; 建立数据采集和录入的标准指南,确保录入数据与数据源的一致性。对于录入过程中的任何修改,需要提供修改原因并留下完整的稽查轨迹。 制定完善的数据质量管理计划,确立关键字段;制定系统质控和人工质控计划,确保数据的真实性、准确性和完整性。数据源核查确认是保证研究数据真实完整的必要措施之一,RWS涉及到大规模的数据,可充分利用系统实时自动逻辑核查来加强质控,降低人工质控成本;对于关键字段,可进行100%原始数据核查(SDV),其他字段可根据实际情况降低核查率。 数据标准化,建议使用标准化字典。RWS信息来源复杂,数据的标准化是保障数据质量的基础和关键环节。 为保障RWS的发展,保证数据的可溯源性和一致性,可运用新技术,充分利用电子化系统,增强系统逻辑核查功能等,加强RWS的数据质量。 七.偏倚和混杂的控制 临床研究中误差的来源可以分为两类:一类是随机误差(randomerror);一类是系统误差(systematicerror),即我们经常提到的偏倚。在RWS的设计和实施中,偏倚是一个需要特别审视的问题。 1.选择偏倚(selectionbias)的控制 选择偏倚是在RWS中比较常见的偏倚。大多数情况下可以通过科研设计来减少或者消除,如采用匹配或者随机的方法。比如临床科研常见的一个实例,某研究数据库里有3000例患者的数据,经过一系列入排之后仅有500人可用于分析,如果其中一部分人因为数据缺失被排除研究,那么就要考虑是否存在选择偏倚的问题,即数据全面完整的患者和因数据缺失而排除的患者之间是否可比,这是一个需要考虑和评估的要点。如果信息缺失的患者因为某种治疗疗效不佳退出,甚至死亡而导致失访,那么排除后的数据而产生的结果会严重影响研究结果的准确性、可靠性以及外推性。 对于选择偏倚需采取的控制方法: 1)严格掌握研究对象的纳入或排除标准。第一,不患与研究因素有关的其它疾病。例如研究吸烟和肺癌的关系,那么就要将慢性阻塞性肺病(COPD)排除出研究人群。第二,在某些方面与病例组可比。如对照组和病例组在基线信息上尽量可比,如年龄,性别,病情严重程度,经济状况等。 2)尽量提高应答率,减少失访率,并对失访的患者进行评价。 3)尽可能采用多种对照。理想的是以人群中全体病例和非病例(或其有代表性的样本)作为研究对象。如以医院病例为研究对象,宜在多个医院选择对象,且最好有2个对照组,其中一个对照组来自社区一般人群;在队列研究中,最好也应设多种对照,以减少选择偏倚对结果的影响。 PRCT的设计也可以视为控制选择偏倚的一种手段。通过随机分组平衡组间已知和未知的预后因素,最大程度提高组间的可比性,将偏倚最小化,从而增强论证强度。后续的随访过程遵从观察性研究的原则,即研究在常规临床实践下进行,尽可能减少对常规治疗的干预,反映真实临床实践中的情况。 2.信息偏倚(informationbias)的控制 信息偏倚主要来自资料收集和解释过程中的错误信息,比如问卷的问题,生物标本的问题,数据管理的问题,设计与分析的问题。而产生这些不正确信息的原因可以是研究对象本身的记忆误差,也可以由研究者的态度或方法不当所致,更重要的是在研究设计过程中对调查表设计,指标设立和检测方法的选择缺乏科学性和合理性,因此要在研究的不同阶段控制和消除影响信息准确性的各种因素。 对于信息偏倚需采取的控制方法: •研究设计阶段: 在研究设计中对暴露因素必须有严格,客观的定义,并力求指标定量化。要有统一、明确的疾病诊断标准,调查表的问题应易于理解和回答,例如:当询问对象是否吸烟时,首先要明确对应于本次研究的吸烟的定义,如:"每日吸烟一支以上连续一年以上。"调查前应开展预调查,充分估计调查实施过程中可能遇到的问题以及各调查项目的可行性。 研究对象应清楚地了解本次研究的目的、意义和要求,以获取其配合和支持。对于涉及生活方式和隐私的问卷,应事先告知对象所有应答均获保密并将得到妥善保管,必要时可采用匿名问卷。调查员需经过严格培训,能正确理解调查的意义、方法和内容,能严谨客观地从事资料收集工作。研究者应定期检查资料的质量,并设立质量控制程序。 •资料收集阶段: 信息偏倚与调查对象的记忆程度有关,在研究中可对同一内容以不同的形式重复询问,以帮助调查对象回忆并检验其应答的可信性。如询问吸烟暴露年数时可问:"你一生中共吸过几年烟"和"你一生中哪几年吸烟,哪几年不吸烟"。为了便于对象理解并准确地定量,可在询问中使用实物如杯子,量匙等来为某些暴露因素如每日饮酒量、盐摄入量等定量。向研究对象提供有关因素的实物照片也可以帮助对象直观地回答。 为了避免主观诱导对象、除了严格培训调查员外,在临床试验和某些现场研究中,应尽可能采用"盲法"以消除主观因素对研究结果的影响。但在采用"盲法"的同时需考虑其伦理学可行性。 研究中的各种测量仪器、试剂和方法都应标准化。应使用同一型号的仪器并定期校验,试剂必须是同一品牌,同一来源并力求同一批号,检测方法要统一,由专人测定。 对于信息偏倚,除了在方法学上杜绝其来源外,对其所致的错误的分类结果,可进一步在资料分析过程中加以测量、校正,并进行相应的灵敏度分析。 3.混杂(confounding)的控制 混杂是一类在RWS中值得全程关注却又无法完全避免和控制的因素,只能尽可能的识别和控制以减小混杂对结果的影响。识别和选择混杂因素,通常是结合临床和流行病学专业知识进行选择。 对于较成熟的领域,任何已有证据提示为混杂的变量都应该考虑;可以基于文献回顾以及研究人员专业领域的知识和理解。对于崭新的领域,考虑那些与疾病有关也可能与暴露有关的因素。如果难以确定,可以在资源允许的条件下,考虑对所有与疾病有关的因素都进行测量,尽可能的收集更多的数据点。 对于混杂的常用的控制方法如下: •限制:研究设计开始阶段,针对某些可能的混杂因素,对研究对象的入排标准加以限制是常用的控制混杂的方法,然而这样会使得研究对象减少。优点在于筛检大量个体,只入选其中一部分,增加了研究对象的同质性(homogeneity),提高了研究的内部有效性,但是缺点是降低了研究效率,可能会影响结果的外推。而限制范围如果太宽或不当,又可能有残余混杂。 •匹配:队列研究中,匹配是暴露者与非暴露者在某因素上的匹配,一旦匹配,原则上即可完全控制匹配因素引起的混杂,不必在统计分析阶段进一步控制。而病例对照研究中,匹配后还需要按照匹配因素进行分层分析,这是控制混杂的必要条件,并且,匹配并非直接控制混杂,而是提高了控制混杂的效率。值得的注意的是要防止匹配过度。 •分层分析:目的在于估计和控制混杂的影响,评估和描述效应修正因子(modifier)不同水平分层中的研究结果。方法是将研究资料按照混杂因素来进行分层。分层分析缺点在于:一次只能分析一种暴露-疾病关联;连续性变量转变为离散性变量,丢失了一定程度的信息,可能造成残余混杂;需要控制的混杂较多时,分层则不是最明智的选择。 •多因素分析:将多个可能的混杂因素变量引入分析模型,可以是多元线性模型,logistic回归,比例风险模型,因子分析等。要点在于在设计阶段和数据采集阶段将可能的混杂因素收集,以便后续纳入分析,有效地控制混杂。 •倾向性评分:在比较不同的治疗方法对疾病的安全性和有效性评价的研究中,不同组别的患者往往没有可比性,比如采取手术治疗的患者和保守治疗的患者在疾病研究程度、年龄和经济负担能力等方面会有较大的不同,这些因素都是评价手术或保守治疗效果的重要的混杂因素,如果不能得到控制和调整,得到的结果往往是不准确的或者是错误的。为了同时控制多种不同混杂因素在两组人群分布的不平衡,可以采用使用倾向性评分的方法。倾向性评分是指在一定协变量条件下,一个观察对象可能接受某种处理(或暴露)因素的可能性。当研究涉及到的混杂因素过多时,如20-30个,进行匹配则变得不现实,严重影响了样本量,而全部进入统计模型会因共线性等问题,使得统计模型无法正常估计效应。在观察性研究中,通过对倾向性评分的分层分析、匹配、回归分析,权重等方法,以期达到控制混杂的目的[14]。 八.证据等级评价 1.正确认识RWS证据等级 循证医学金字塔证据分级(hierarchyofevidence)方法[15]最早诞生于治疗研究领域,证据分级的概念提出来之初,将所有RCT的证据级别置于其他研究之上,由此导致普遍的观念认为RWS的证据等级或可信度低于RCT研究产生的证据。然而,不同的研究问题需要选择不同类型的研究证据,因为有些临床问题难以用RCT设计去回答。例如,针对糖尿病并发慢性肾炎的患者10年的心血管死亡率评估这一问题,最优的证据来源不是RCT,而是高质量的队列研究。美国FDA于2016年12月在《新英格兰医学杂志》上发文指出[3],RWS与其他证据的本质区别不在于研究方法和试验设计,而在于获取数据的环境。2017年8月美国FDA发布《使用真实世界证据支持医疗器械注册审批指南》提出随着真实世界临床研究的增多,可以利用这些证据用来支持医疗器械的监管决策[2]。可见RWE甚至可以作为药械审批的支持性证据内容,是循证医学体系中的有效补充。因此,把RWS的证据级别简单划分在金字塔证据分级法中的某个或某几个级别并不适合,也不意味着通过RWS所产生的证据等级一定低于RCT证据,两者往往是为了回答不同临床问题而产生的不同研究设计,在证据级别上不具备简单的可比性。 2.RWE评价方法 随着医学研究领域的发展,证据评价体系也需要相应拓展以适应新的需求。对RWS的证据等级评价应该依据选取的研究设计与研究问题之间的相关性、研究质量控制程度,以及选取的研究数据的可靠性进行评价。本文借鉴循证医学金字塔证据分级方法[16],将常见的RWS类型按照证据等级的高低进行排序(图2),同时建议研究者参照一系列影响证据等级的关键因素来客观评估真实世界证据的证据级别,例如,以下表格(表3)中的关键点均是提高真实世界证据等级的常见关键因素[17],反之,则降低研究的证据级别。
九.案例分析 “以人群为基础的甲状腺癌患者死亡概率的预测和评价研究”,是2013年发表在JournalofClinicalOncology的一篇基于已有数据库的RWS文章[18]。我们参考STROBE质量评估标准和指南流程中涉及的相关要素[17],对该研究进行了如下分析。
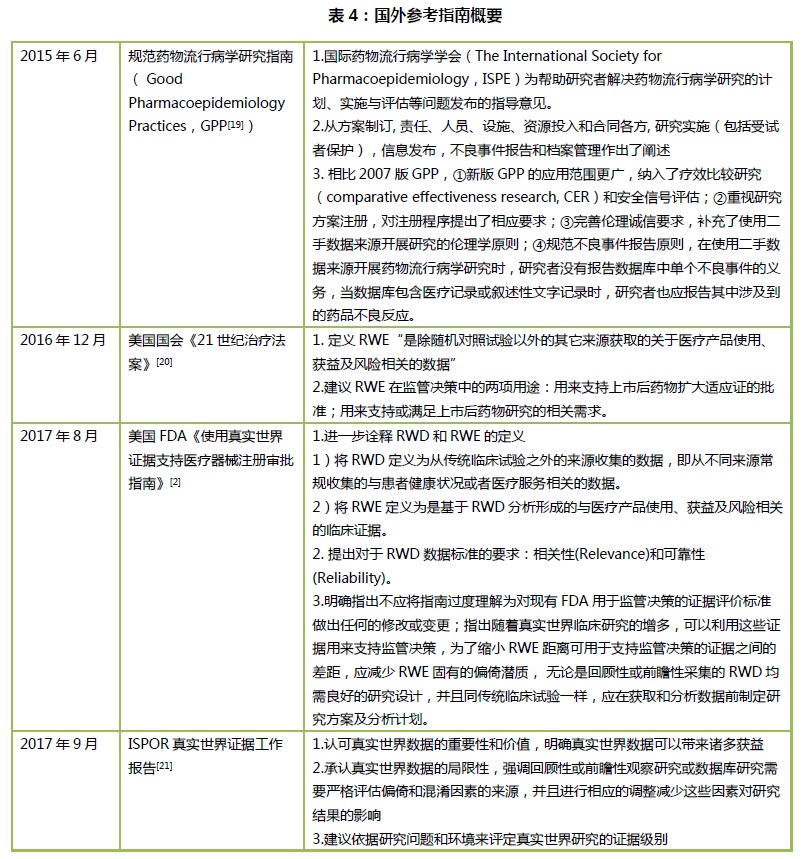
十.新技术方案及未来展望 21世纪是数据引导决策的时代。计算机技术支持的临床实践所产生的大量临床数据为进行科学研究奠定了基础。在海量数据背景下,可基于现有数据库中的数据进行分析,来支持不同种类的业务。随着机器学习的发展,图像识别,文本识别,声音识别等新技术可以快速帮助临床数据结构化,大数据分析方法,云储存及云计算等技术的逐渐成熟以及区域链技术(blockchain)的提出和应用,使多维度数据整合及一体化管理成为可能。这些都给RWS带来了前所未有的便利,为RWS的开展和长期应用奠定了基础。 真实世界证据作为一个较新的概念,还存在着一些有争议的内容,其相关技术方法也还有待完善,目前仅作为药品和医疗器械审批决策的补充证据。然而,真实世界证据对于未来健康和医疗的推动不可低估。本指南仅针对RWS提出建议性思考,在具体临床科研实践中,研究人员可根据具体情况灵活参考和使用该指南。希望该指南能够帮助研究人员快速入门并解决临床实际问题。鉴于该指南为初版,还有非常多不足和需要优化的空间,非常期待大家的宝贵意见和反馈,在此基础上我们将逐步完善,在未来的3到5年时间里,建立起完全符合中国实际需求的RWS指南体系。 附录I国外指南参考 近年来国际上多个临床研究组织和监管机构先后颁布了关于RWS的指南或工作指导意见,例如有GoodPharmacoepidemiologyPractice(GPP),ISPORRWD指南,USFDADeviceRWD指南等,本文以表格的形式简要总结几个重要国外指南的要点。
附录II参考文献 1. U.S. Department of Health and Human Services, Food and Drug Administration, Center for Devices and Radiological Health, Center for Biologics Evaluation and Research. Use of Real World Evidence to Support Regulatory Decision Making for Medical Devices. Guidance for industry and FDA staff.Document issued on August 31,2017. 2. CFDA.关于深化审评审批制度改革鼓励药品医疗器械创新的意见[S]. 2017.10.08. 3. Sherman RE, Anderson SA, et al. Real-World Evidence - What Is It and What Can It Tell Us? N Engl J Med. 2016 Dec 8;375(23):2293-2297 4. https://www.ncbi.nlm.nih.gov/books/NBK3827/#pubmedhelp.Clinical_Queries_Filters 5. 观察性疗效比较研究的方案制定:使用者指南 平装 –Priscilla Velentgas (作者), Nancy A.Dreyer (作者),Parivash Nourjah (作者), Scott R.Smith (作者), 等, 詹思延 (译者). 2014.8.1. 6. National Ethics Advisory Committee. Ethical Guidelines for Observational Studies: Observational Research, Audits and Related Activities. Revised edition. Wellington, New Zealand: National Ethics Advisory Committee; 2012. 7. U.S. Department of Health & Human Services. Health and Human Service (HHS) Subjects Regulations. 45 CFR 46.116[EB/OL];2009. 8. Sackett DL, Strauss SE, Richardson WS, et al. Evidence-based medicine: how to practice and teach EBM. Edinburgh: Churchill Livingstone, 2000. 9. 唐立等.实效性随机对照试验:真实世界研究的重要设计. 中国循证医学杂志, 2017,17(9):999-1004 10. Jones WS, Roe MT, Antman EM, et al. The changing landscape of randomized clinical trials in cardiovascular disease. J Am Coll Cardiol 2016; 68(17):1898–1907. pmid:27765193 11. Center of Drug Evaluation, CFDA. Technical Guidelines for Data Management in Clinical Trials (临床试验数据管理工作技术指南) [S]. 2012.http://www.cde.org.cn/news.do?method=largeInfo&id=312673. 12. FDA. Guidance for Industry Computerized Systems Used in Clinical Trials [S].http://www.fda.gov/ohrms/dockets/98fr/04d-0440-gdl0002.pdf. 13. EMA. Reflection Paper on Expectations for Electronic Source Data and Data Transcribed to Electronic Data Collection Tools in Clinical Trials [S]; 2010. http://www.ema.europa.eu/docs/en_GB/document_library/Regulatory_and_procedural_guideline/2010/08/WC500095754.pdf. 14. Rosenbaum, Paul R.; Rubin, Donald B. The Central Role of the Propensity Score in Observational Studies for Causal Effects. Biometrika. 1983, 70 (1): 41–55. 15. Campbell DT,Stanley JC. Experimental and quasi-experimental designs for research[M]. Chicago,IL:Rand Mc- Nally College,1963: P5 - 6. 16. http://www.gradeworkinggroup.org/ 17. STROBE statement--checklist of items that should be included in reports of observational studies (STROBE initiative). et al. Int J Public Health.(2008) 18. Yang L, Shen W, Sakamoto N. Population-based study evaluating and predicting the probability of death resulting from thyroid cancer and other causes among patients with thyroid cancer[J]. Journal of Clinical Oncology: Official Journal of the American Society of Clinical Oncology, 2013, 31(4):468. 19. Public Policy Committee,International Society of Pharmaco- epidemiology. Guidelines for good pharmacoepidemiology practice (GPP) [J]. Pharmacoepidemiol Drug Saf, 2016, 25(1): 2-10 20. H.R.6 - 21st Century Cures Act. https://www.congress.gov/bill/114th-congress/house-bill/6 21. Garrison, Louis P. et al. Using Real-World Data for Coverage and Payment Decisions: The ISPOR Real-World Data Task Force Report. Value in Health, 2017, Volume 10 , Issue 5 , 326 – 335 组长: 吴一龙 陈晓媛 杨志敏 执笔专家(按汉语拼音): 程颖 陆舜 宁毅 唐智柳 田志钢 王洁 吴婷 徐晋小 夏素琴 余秋琼 周清 指南编委会专家成员(按汉语拼音): 方维佳 高培 谷成明 马飞 毛磊 王学兴 阎昭 张博恒 朱昊 周脉耕 钟文昭 鸣谢:非常感谢各位行业专家给予的大力支持,没有大家的齐心协力,我们的指南无法如此顺利的完成,也特别感谢新屿信息科技(上海)有限公司在指南撰写过程中给予的大力支持!
|




- 上一篇:没有了
- 下一篇:脓毒症诊断与治疗规范